

テレビ番組やSNSのアンケートで「100人に聞きました!」という言葉をよく目にしますよね。
そんなとき、
「たった100人の意見で、日本全体のことがわかるの?」
「たまたまその100人が偏っていただけじゃないの?」
と疑問に感じたことがある人も多いのではないでしょうか。
実は、この「一部から全体を推測する」手法こそが、統計学の要である「サンプリング(標本抽出)」です。
今回は、サンプリングの仕組みと、数字に騙されないためにチェックすべきポイントを解説します。
サンプリングとは?
統計学における「サンプリング(標本抽出)」の基本概念と、それがなぜ必要なのかについて解説します。
- サンプリングとは?
- 押さえておきたい2つの重要用語
- なぜ「全員」を調査しないのか?
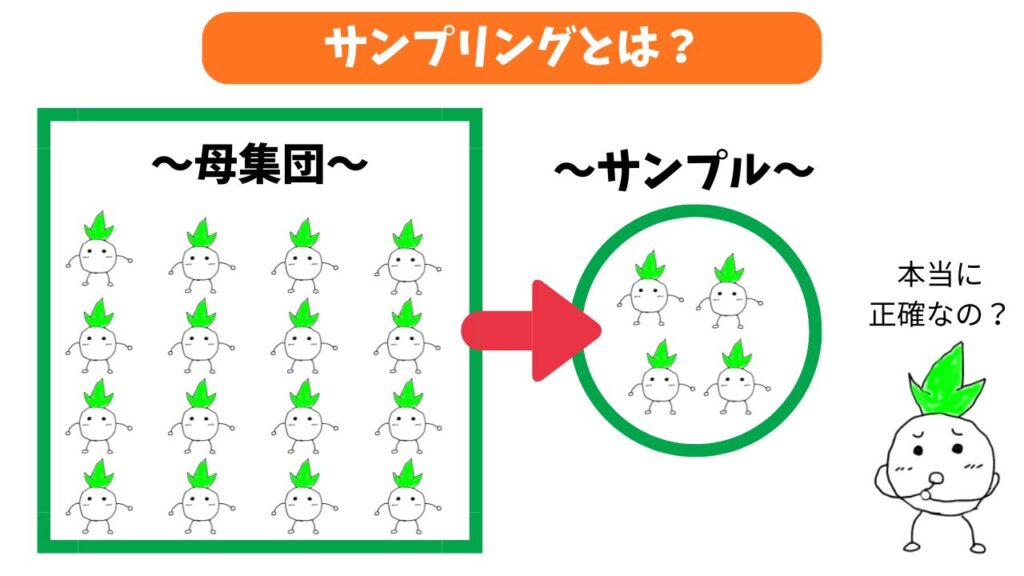
サンプリングとは?
サンプリングとは、調べたい対象の「すべて」を調べるのではなく、その中から「一部だけを抜き出して全体の特徴を推測する」統計手法です。
テレビの視聴率や選挙の「当選確実」のニュースをイメージしてみてください。
日本中の全世帯のテレビや全有権者の投票用紙を一枚残らず調べようと思うと、とてつもない時間と費用がかかってしまいますよね。
そこで、全体の中から偏りが出ないように一部のデータだけを選び出し、その結果から「全体ではこうなっているはずだ」と論理的に予測を立てます。
つまり、サンプリングとは、時間やコストを賢く節約しながら限られたデータから「全体の姿」を正確にあぶり表すための、統計学における最も基本で強力なテクニックといえます。
押さえておきたい2つの重要用語
サンプリングの仕組みを理解する上で、基本となる2つの言葉があります。
- 母集団(ぼしゅうだん): 調査したい対象となる「全体」のこと。(例:日本国民全員、全高校生など)
- サンプル(標本): 母集団の中から、実際に調査を行うために「抜き出された一部」のこと。
つまりサンプリングとは、「母集団という大きな全体の中から、サンプル(一部のデータ)を抽出して分析するプロセス」そのものを指します。
なぜ「全員」を調査しないのか?
サンプリングの話を聞くと、
「一部だけではなく、全員に調査した方が正確な結果が出るのでは?」
と感じる人も多いかもしれません。
確かに、理想をいえば全員を調べる「全数調査」が最も正確なデータになります。
しかし、先ほども述べたように、現実問題として全数調査を常に行うのは不可能です。
- 膨大なコストと時間: 例えば、日本国民(約1億2,000万人)のデータを全数調査で集計しようとすれば、天文学的な費用と何年もの年月がかかってしまいます。
- 身近な規模でも困難: 国レベルの話でなくとも、例えば「学生数1万人の総合大学」で全員から一人残らずアンケートを回収するだけでも、想像以上の労力が必要になります。
このように、限られた時間と予算(コスト)の中で、現実的に「全体の傾向」をいち早く掴むためには、全員を調べるのではなく、全体を反映した一部を調べる「サンプリング」が絶対に欠かせない手法になります。

なぜ“100人”でも全体がわかるのか
「たった100人の意見で、どうして全体の傾向がわかるの?」
統計やアンケートの調査結果を目にしたとき、誰もが一度はこのような疑問を抱くのではないでしょうか。
ここでは、一部のデータから全体を推測する「サンプリング(標本抽出)」という手法が、なぜ統計学的に信頼できるのかを3つのポイントで詳しく解説します。
- 「ランダム(無作為)」に選ぶことで全体の縮図ができる
- サンプリングは「スープの味見」と同じ原理
- サンプル数と結果の安定性の関係
「ランダム(無作為)」に選ぶことで全体の縮図ができる
サンプリングを成功させる上で最も重要な絶対条件は、「ランダム(無作為)」にデータを選ぶことです。
調査を行う際、特定の意図や先入観を持たず、完全に「くじ引き」のような公平な状態で母集団(対象となる全体)からデータを抽出します。
このように人為的な偏りを徹底的に排除して選ばれた少数のサンプルは、年齢層や男女比、意見の割合などがそのまま反映された「母集団のミニチュア版」になります。
つまり、選び方さえ公平であれば、少人数であっても全体の性質をしっかりと引き継ぐことが可能です。
サンプリングは「スープの味見」と同じ原理
データの一部を取り出して全体を推測する仕組みは、よく「スープの味見」に例えられます。
大きな鍋でたくさんのスープを作っている場面を想像してみてください。
味の確認をするとき、わざわざ鍋のスープを全部飲み干す人はいませんよね。お玉ですくった一口分の味見だけで、鍋全体の味を正しく判断できるはずです。
これがサンプリングの基本的な考え方であり、「一部を調べれば全体がわかる」という大きな根拠になります。
ただし、この味見が正確であるためには重要な条件があります。
それは「事前によくかき混ぜること」です。
もし、塩を振った直後にかき混ぜることなく表面だけをすくって味見をしたらどうなるでしょうか。
しょっぱすぎたり味がしなかったりと、鍋全体の本当の味はわかりません。鍋底からしっかりとかき混ぜて全体を均一にする作業こそが、統計における「ランダム抽出」の役割を果たしています。
サンプル数と結果の安定性の関係
それでは、実際にどれくらいの人数を調べれば全体を正確に推測できるのでしょうか。
基本的には、サンプル数(調べる人数)が多くなるほどデータは安定し、実際の全体とのズレ(誤差)は小さくなっていきます。
とはいえ、何万人、何百万人も調べる必要はありません。
調査内容にもよりますが、統計学の計算上、「1,000人〜2,000人」のデータが適切に集まれば、日本の全人口の意見であっても、誤差をわずか数%以内に収めて高い精度で推測できるとされています。
テレビの視聴率や選挙の出口調査などが、ごく一部の人への調査をもとに正確な全体像を導き出せるのも、このサンプリングの理論がしっかりと働いているためです。
実は怖い⁉︎「偏り(バイアス)」の落とし穴
サンプリングにおいて、最も注意しなければならないのが「偏り(バイアス)」です。
スープでいうと、かき混ぜられていない状態です。
このような場合はサンプリングの結果が実態を表さないことが多くなってしまいます。
それでは、どのような場合に偏りが起こってしまうのかみていきましょう。
- 若者や年配者に偏りが多い場合
- 地方や都市部に偏りが多い場合
- ネットでのアンケート
若者や年配者に偏りが多い場合
例えば、「最近の政治についてどう思いますか?」という調査を原宿で100人に聞いたとします。
この場合、原宿という土地柄から、アンケート調査の回答者のほとんどは若者になりますよね。
もし、この調査の結果を「日本国民の意見」として発表した場合、世の中の実態を表しているといえるのでしょうか?
この調査では高齢者や働く世代の意見が抜け落ちているため、結果は大きく歪んでいると考えられますよね。
反対に、巣鴨のように高齢者の多い街で調査を行なっても、同じように結果は大きく歪んでいると考えられます。
今回の政治に関する調査を
「原宿の若者100人に聞いた!」
「巣鴨の高齢者100人に聞いた!」
という見出しで公表するのであればサンプリング調査として正しいのですが、
「都民100人に聞いた」
「日本国民100人に聞いた」
とした場合、実態を反映しているとはいえなくなります。
地方や都市部に偏りが多い場合
例えば、「通勤通学の手段」や「日常生活での移動手段」についてのアンケート調査を都心部で100人に聞いた場合、「電車」と答える人がほとんどですよね。
この結果をもとに、「日本人のほとんどは移動手段として電車を利用している」と結論づけて良いでしょうか?
答えは「いいえ」ですよね。
というのも、日本の地方都市や田舎では電車よりも車を利用する人が多く、通学に関しては徒歩や自転車の割合も大きくなると考えられるからです。
このように、調査を行う場合、「特定地域への偏り」が大きくなってしまうと実態を反映しない可能性が高まります。
ネットのアンケート
スマホの流通により、ネットを使ったアンケート調査も多くなっていますよね。
ネット調査は手軽である一方で、「そのサイトの利用者」や「ネットを頻繁に使う人」だけに偏る傾向があります。
年齢や地域だけでなく、特定の趣味嗜好を持つ人が集まる場所での調査も全体の縮図にはなりにくくなります。
このように、統計学では「何人(数)に聞いたか」だけでなく「誰(質)に聞いたか」もとても重要になります。
信用できる調査か見抜くチェックポイント
ニュースの数字を見たとき、次の4点をチェックしてみてください。
- ランダムに抽出されているか: 調査対象が偏りなく、公平に選ばれているか。
- サンプル数は十分か: 100人でも傾向はわかりますが、全国調査なら1,000人程度あると信頼性が高まります。
- 対象に偏りはないか: 性別、年齢、居住地に偏りがないか。
- 質問の仕方は適切か: 「〇〇は問題だと思いませんか?」といった、特定の回答を誘導するような聞き方をしていないか。
テレビのニュースなどでは、「どこどこの何人に聞きました」のように、どこで行なった調査(ネット、街頭インタビューなど)なのかを発表しているので、その情報までしっかり把握しましょう。
また、特にSNSではニュースの調査結果の画像のみを切り取って「調査結果」として情報が流れていることが多いので、「どのような調査なのか」がわからない限りは簡単に鵜呑みにしないことも大切です。
よくある誤解とは?
ここでは、サンプリングについてのよくある誤解を紹介していきます。
- 「人数が多ければ正確」は本当?
- ネットでの調査はダメ?
- 100人は少ない?
「人数が多ければ正確」は本当?
人数(サンプル数)が多いと一般的にデータの正確性は高いとされていますが、必ずしも正確になるとはいえません。
例えば1万人に「移動手段」のアンケートを取っても、その1万人がランダムではなく「特定の地域の住民(東京など)」に偏ってしまっている場合、全体の意見としては不正確です。
サンプリングは「サンプル数」も大事ですが、何よりも「サンプルの選び方」が重要です。
ネットでの調査はダメ?
先ほど「ネットのアンケートは偏りが発生する可能性がある」と解説しましたが、ネット調査自体が悪いわけではありません。
最近では、年齢や性別の比率を人口構成に合わせて調整するなど、偏りを補正する高度な手法が使われています。
さらに、ここ数年ではネットを扱える世代が増えていることやアンケートの回答が簡単になったことから、以前よりも偏りが起こりにくくなっています。
100人は少ない?
100人のサンプル数は少ないと感じるかもしれませんが、正しく抽出しているのであればそれなりの精度であるといわれています。
国民全員に反映させるなら100人は少ないかもしれませんが、市町村などの地域や学校内の調査などであれば100人のサンプル数は十分といえます。
まとめ
サンプリングは、膨大なデータの世界から真実を効率よく見つけ出す、非常に便利な道具です。
とはいえ、万能な技法というわけではなく、以下のような特徴を知っておく必要があります。
- サンプリングは便利だが「偏り」に弱い。
- 抽出がランダムであることが前提。
- サンプル数だけでなく「誰に対して、どうやって聞いたか」が重要。
アンケートや視聴率など、日常で使われているデータの多くはサンプリングが使われています。
サンプリングの仕組みを知ることで、正しくデータを読み取ることができるようになるだけでなく、自分でデータを収集して分析できるようになります。
皆さんもぜひ、データを取り扱う際にはサンプリングを使ってみてはいかがでしょうか!




コメント